3.4.1 第一次全體標註與配對組形成
在教授指示下,全員共同標註相同的 100 句評論,依一致率分組為 7 組;高田整合 7 組 JSON 結果轉為 CSV,完成首次一致率分析。
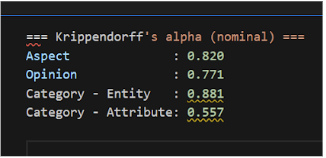
小笠原與甲斐在 Category 標註較弱,需再練習。
本階段發現之問題
- 資料 ID 重複或遺漏
- Aspect 欄位空白(未填 NULL)造成欄位位移
- 手動輸入造成表達不一致與錯誤
- 應拆分為多個 Aspect 卻被誤合併
→ 立即再確認標註規則並修訂作業流程。
在資料蒐集後,本研究進行 面向(Aspect)、評價詞(Opinion)、情感極性 (Sentiment) 等標註之資料前處理作業。此外,為進行句子層級分析,我們使用 Python 進行評論句子切分及屬性標註。
・原始資料

・前處理後的資料

透過前處理,我們成功為每句評論新增 aspect(面向)、opinion(評價詞)、sentiment(情感極性)、entity(實體)、sentence(句子)、hotel_id(飯店編號)等資訊。然而,指導教授指出資料仍存在下列問題:
・原始資料
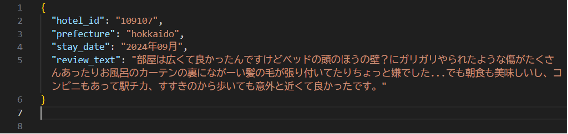
・處理後的資料
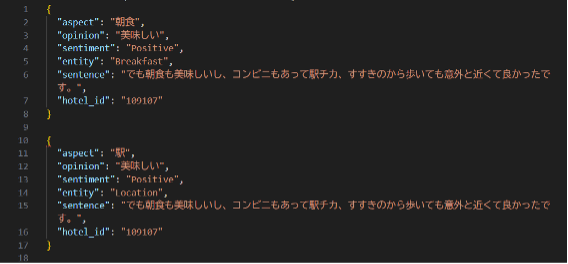
如例所示,「車站(location)」的面向在標註後被錯誤歸類為「美味」這類評價詞,顯示僅依賴詞語共現容易造成錯誤分類。
本次初步標註並未明確界定評論中的 Entity(評價對象)與 Attribute(評價角度)。教
授因此要求:
● 重新定義并統一 Entity/Attribute
● 情感極性(Sentiment)須人工標註
● 根據教授提供之先行研究 Python 工具重新調整程式
研究方針之調整
Entity、Attribute 依教授指定之論文分類方式
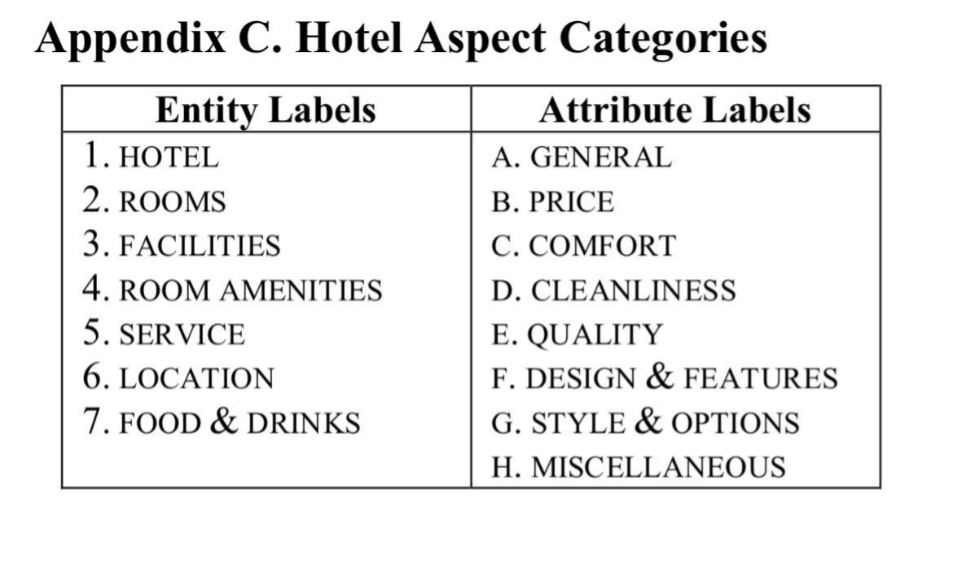
● 調整教授提供之程式,作為手動 ABSA 標註工具
● 兩人一組,個別標註 50 筆,並相互比對一致性
● 一致率(相符率)目標至少為 70%
使用改良後的工具,我們對評論資料逐句進行人工標註並比較兩名成員之結果。
・工具輸入畫面
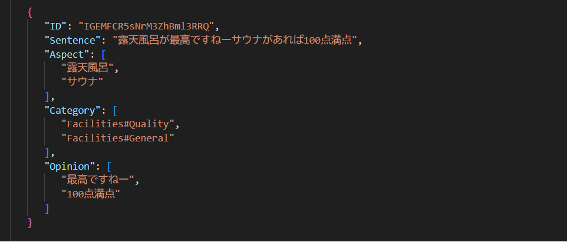
標記結果 A
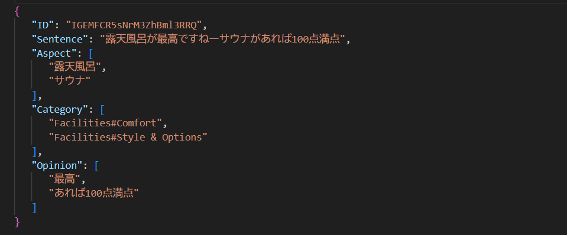
標記結果 B
研究團隊以「分階段回饋 → 工具優化 → 規則再統一」的節奏推進 ABSA 標註工作,以下依 時序整理三階段重點。
在教授指示下,全員共同標註相同的 100 句評論,依一致率分組為 7 組;高田整合 7 組 JSON 結果轉為 CSV,完成首次一致率分析。
小笠原與甲斐在 Category 標註較弱,需再練習。
→ 立即再確認標註規則並修訂作業流程。
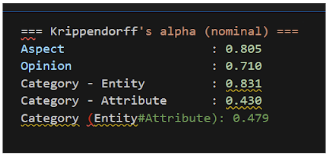
暑假期間每週召開會議,逐條統一標註規範,並重新檢視一致率計算方式避免重複計數。
再標註後 Category 一致率改善有限,教授要求重新設計演算法。
第二次結果:
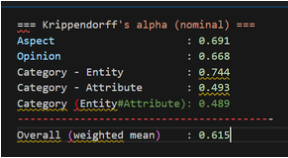
高田調整 JSONL 結構,溝上分發 8 月資料集並整併 7 月成果。教授於例會中示範 Final (兩人交叉產生正解資料)的作業流程並明確分派任務。
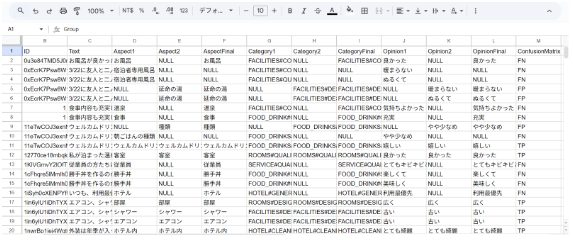
Final 期間陸續偵測到資料錯誤,團隊依教授回饋「即查即修」,歷經多輪疊代後完成 7 名成員全部 Final 標註,正式產生正解資料集。
教授講解 Value Annotation(VA)並開放專屬網站,全員註冊後先進行 35 句試標註,再依 時間表執行大量任務。
作業里程碑
最終每人完成 550 句 VA 標註;高田依教授指示於 Notion 記錄錯誤樣態。
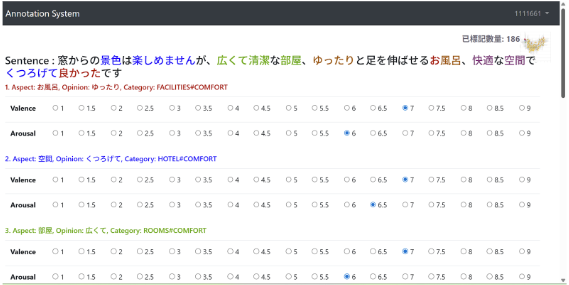
團隊將最終標註資料整理為 JSONL,提交至 SemEval-2026 主辦之 Codabench 平台,參加 Task 3:Dimensional Aspect-Based Sentiment Analysis(DimABSA)Track A。
以 Transformer(如 BERT-base)為基礎,添加迴歸層進行微調:
採用 Instruction Tuning 之大型語言模型,強調多語多任務能力: