4.4.1 克服多人標註一致性
期中階段遭遇以下挑戰:
- 面向詞/評價詞邊界模糊
- 抽象面向分類標準不明確
- 類別依賴語境而變動
- 中立、委婉表達難以判讀
對策:
- 暑期每週召開會議,逐條釐清 Miscellaneous、Comfort、Quality、Style & Options、Design & Features。
- 導入 QC:逐批量測一致率、分析原因、低一致率組別強制討論。
結果:一致性顯著提升,已能達到直接提交標準。
以下列出實際進行標記的評論句,以及從中所抽取出的面向詞(Aspect)與評價詞(Opinion)的範例:
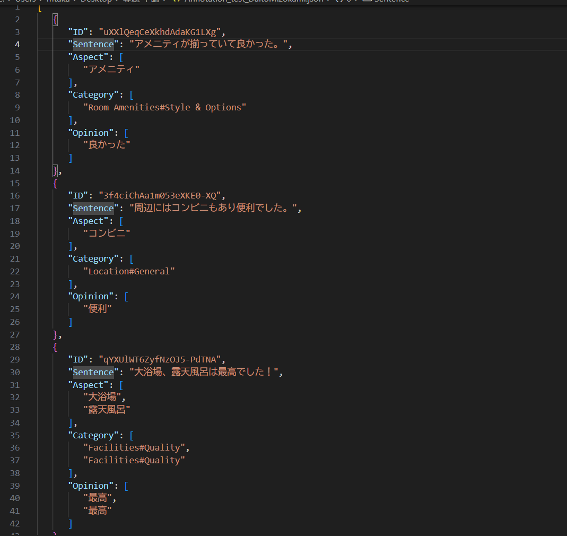
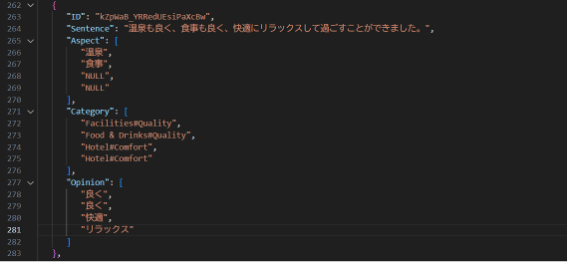
從標註結果中,我們觀察到:
● 面向詞多集中於「早餐」、「房間」、「地點」、「服務」等評價重點。
● 單一句子同時包含多個面向詞之情況相當普遍,如:「房間很乾淨,溫泉也很不
錯」。
● 評價詞的表現形式多樣,包括形容詞(「方便」、「乾淨」、「滿意」、「狹窄」、
「失望」)及副詞結構(「非常」、「有點」、「超級」)。
此類語言特徵可作為後續建立 情感強度(Valence/Arousal)分析 的重要基礎資訊。
期中階段遭遇以下挑戰:
對策:
結果:一致性顯著提升,已能達到直接提交標準。
為解決中立、反諷、多層次情感難以標註的問題,我們加入 Valence(V:愉悅—不快) 與 Arousal(A:覺醒—鎮靜) 兩軸量表。
透過系統化流程與 QA 管控,資料集具備高度實用性並成為後續模型訓練核心資產。
本系統提交至 Codabench(SemEval-2026 Task 3 Track A),以下為 Dev Set 評估摘要與各子任務表現。
| 子任務 | 課題名稱 | 排名指標 |
|---|---|---|
| Subtask 1(DimASR) | 情感回歸(VA 預測) | Normalized RMSE |
| Subtask 2(DimASTE) | 三元組提取 | Continuous F1(cF1) |
| Subtask 3(DimASQP) | 四元組提取 | Continuous F1(cF1) |
| 模型 | 使用的模型名稱(ID) | RMSE VA | PCC V (↑) | PCC A (↑) |
|---|---|---|---|---|
| 日文(單詞級別) | cl-tohoku/bert-base-japanese-whole-word-masking | 1.9908 | 0.1026 | 0.0761 |
| 多語言 | bert-base-multilingual-cased | 2.0561 | 0.0198 | 0.0850 |
| 日文(字符級別) | cl-tohoku/bert-base-japanese-char-v3 | 2.0866 | 0.0610 | 0.0219 |
考察:
| 模型 | 使用的模型名稱(ID) | cF1 (↑) | cPrecision (↑) | cRecall (↑) |
|---|---|---|---|---|
| Qwen (8B) | unsloth/Qwen3-8B-unsloth-bnb-4bit | 0.4359 | 0.4273 | 0.4449 |
| Qwen (4B) | unsloth/Qwen3-4B-Instruct-2507-bnb-4bit | 0.4027 | 0.3679 | 0.4447 |
| Gemma (9B) | unsloth/gemma-2-9b-it-bnb-4bit | 0.1078 | 0.0613 | 0.4485 |
考察:
| 模型 | 使用的模型名稱(ID) | cF1 (↑) | cPrecision (↑) | cRecall (↑) |
|---|---|---|---|---|
| Qwen (4B) | unsloth/Qwen3-4B-Instruct-2507-bnb-4bit | 0.3342 | 0.3360 | 0.3323 |
| Qwen (8B) | unsloth/Qwen3-8B-unsloth-bnb-4bit | 0.2942 | 0.3155 | 0.2756 |
| Gemma (9B) | unsloth/gemma-2-9b-it-bnb-4bit | 0.1144 | 0.0978 | 0.1378 |
考察:
持續優化標註規則、降低 FP/FN,並探索多模態與跨語言增益策略,以進一步提升 DimABSA 表現。